
A recent computer has enough resources and thus we might not have the opportunity to reduce memory usage. However, it’s worth knowing how to reduce memory usage by sorting variable declaration order in a struct. Let’s have a look at it together here.
The variable order in struct matters
Do you know how many bytes this struct uses?
type myStruct struct {
boolValue bool
middleValue int64
boolValue2 bool
}It’s 2 * bool (1 byte) + 1 * int64 (8 bytes)… Therefore, 10 bytes? No. It’s actually 24 bytes.
Let’s check the actual code to show the used bytes. We create the following generic struct so that we can change the data type of middleValue.
type memory1[T constraints.Ordered] struct {
boolValue bool
middleValue T
boolValue2 bool
}Let’s see the result below.
fmt.Println(unsafe.Sizeof(memory1[int8]{})) // 3
fmt.Println(unsafe.Sizeof(memory1[int16]{})) // 6
fmt.Println(unsafe.Sizeof(memory1[int32]{})) // 12
fmt.Println(unsafe.Sizeof(memory1[int64]{})) // 24The total defined bytes, which is the sum of the data types, are the same as the actual size if the middle data type is 1 byte. However, the result is different if the middle data type is not 1 byte.
Let’s change the order in the struct.
type memory2[T constraints.Ordered] struct {
boolValue bool
boolValue2 bool
lastValue T}Then, the total used bytes are less than the previous version.
fmt.Println(unsafe.Sizeof(memory2[int8]{})) // 3
fmt.Println(unsafe.Sizeof(memory2[int16]{})) // 4
fmt.Println(unsafe.Sizeof(memory2[int32]{})) // 8
fmt.Println(unsafe.Sizeof(memory2[int64]{})) // 16What’s going on here?
How to check the offset in a struct
We confirmed that the total byte size changes depending on the order in a struct. What we should do next is to know the reason. The padding is the key here. Let’s check on which address each variable exists.
We can check it with the following function.
func checkStructInfo(obj any) {
value := reflect.ValueOf(obj)
fmt.Printf("struct size for [%s] is %d (any: %d)\n", value.Type().Name(), value.Type().Size(), unsafe.Sizeof(obj))
for i := 0; i < value.Type().NumField(); i++ {
typeField := value.Type().Field(i)
field := value.Field(i)
fmt.Printf(" %-10s: (offset: %d, align: %d, size: %d)\n", typeField.Name, typeField.Offset, field.Type().Align(), field.Type().Size())
}
}Check the following post too if you don’t know how to extract data from any/interface.

Let’s call the function for int16, int32, and int64.
checkStructInfo(memory1[int16]{})
// struct size for [memory1[int16]] is 6 (any: 16)
// boolValue : (offset: 0, align: 1, size: 1)
// middleValue: (offset: 2, align: 2, size: 2)
// boolValue2: (offset: 4, align: 1, size: 1)
checkStructInfo(memory1[int32]{})
// struct size for [memory1[int32]] is 12 (any: 16)
// boolValue : (offset: 0, align: 1, size: 1)
// middleValue: (offset: 4, align: 4, size: 4)
// boolValue2: (offset: 8, align: 1, size: 1)
checkStructInfo(memory1[int64]{})
// struct size for [memory1[int64]] is 24 (any: 16)
// boolValue : (offset: 0, align: 1, size: 1)
// middleValue: (offset: 8, align: 8, size: 8)
// boolValue2: (offset: 16, align: 1, size: 1)As you can see in the result, there is an offset for each variable.
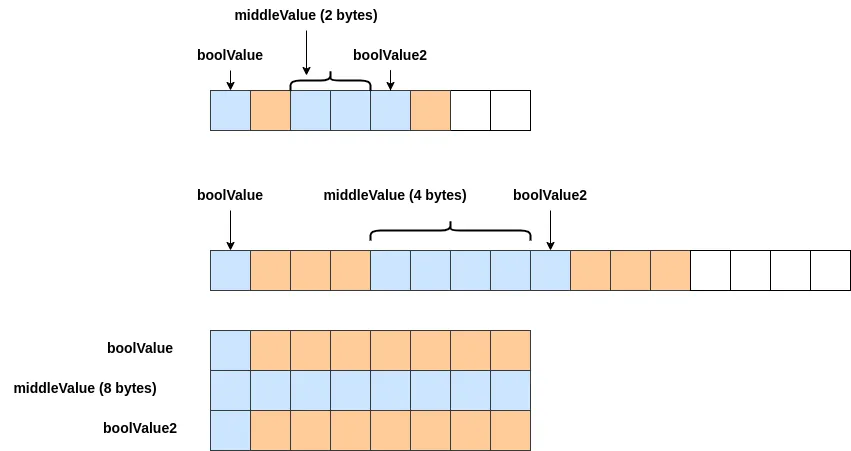
The offset position depends on the middle data type.
If the middle data type has 4 bytes, the offset is 4x, namely 0, 4, 8, 12…
If it’s 8 bytes, the offset is 8x, namely, 0, 8, 16, 24…
The data are not on the consecutive addresses when different data types exist in a struct. That’s why the total byte size changed depending on the order.
Let’s check the result for another struct.
checkStructInfo(memory2[int16]{})
// struct size for [memory2[int16]] is 4 (any: 16)
// boolValue : (offset: 0, align: 1, size: 1)
// boolValue2: (offset: 1, align: 1, size: 1)
// lastValue : (offset: 2, align: 2, size: 2)
checkStructInfo(memory2[int32]{})
// struct size for [memory2[int32]] is 8 (any: 16)
// boolValue : (offset: 0, align: 1, size: 1)
// boolValue2: (offset: 1, align: 1, size: 1)
// lastValue : (offset: 4, align: 4, size: 4)
checkStructInfo(memory2[int64]{})
// struct size for [memory2[int64]] is 16 (any: 16)
// boolValue : (offset: 0, align: 1, size: 1)
// boolValue2: (offset: 1, align: 1, size: 1)
// lastValue : (offset: 8, align: 8, size: 8)Two bool variables are defined in a row. Therefore, the memory is efficiently used in this case.
Struct, map, or slice in struct
How about having a struct, map, or slice in a struct? Let’s see struct in struct first.
type hasStruct struct {
memory1 memory1[int32]
memory2 memory2[int32]
}
// struct size for [hasStruct] is 20 (any: 16)
// memory1 : (offset: 0, align: 4, size: 12)
// memory2 : (offset: 12, align: 4, size: 8)The internal struct already has padding. Therefore, the total size of the parent bytes is simply the sum of the two struct sizes.
How about map and slice?
type hasMapAndSlice struct {
boolValue bool
mapValue map[int8]int64
sliceValue []int64
}
// struct size for [hasMapAndSlice] is 40 (any: 16)
// boolValue : (offset: 0, align: 1, size: 1)
// mapValue : (offset: 8, align: 8, size: 8)
// sliceValue: (offset: 16, align: 8, size: 24)Map and slice are always respectively 8 bytes and 24 bytes. It depends on the system arch (32 or 64 bits) though.
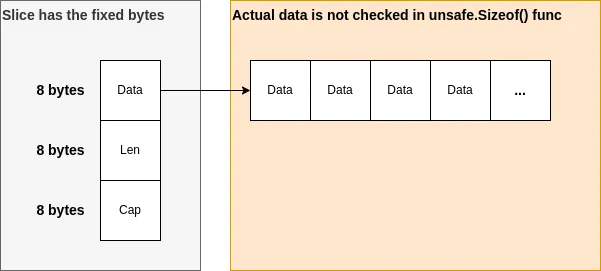
This is the representation of a slice (See the official page too). If the system is 64-bits system, the total size is 24 bytes. Data doesn’t have actual value but a pointer. Therefore, it is always the same size even though it has many elements.
type SliceHeader struct {
Data uintptr
Len int
Cap int
}
The official page explains it in detail.
I couldn’t find the map explanation but I guess it’s similar to slice.
How about string?
String also has a similar representation (See official page too).
type StringHeader struct {
Data uintptr
Len int
}Look at the following.
strObj := memory1[string]{}
fmt.Printf("%p, size: %d, align: %d\n", &strObj, unsafe.Sizeof(strObj), unsafe.Alignof(strObj))
// 0xc00006e020, size: 32, align: 8
checkStructInfo(strObj)
// struct size for [memory1[string]] is 32 (any: 16)
// boolValue : (offset: 0, align: 1, size: 1)
// middleValue: (offset: 8, align: 8, size: 16)
// boolValue2: (offset: 24, align: 1, size: 1)
strObj.middleValue = "123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890"
checkStructInfo(strObj)
// struct size for [memory1[string]] is 32 (any: 16)
// boolValue : (offset: 0, align: 1, size: 1)
// middleValue: (offset: 8, align: 8, size: 16)
// boolValue2: (offset: 24, align: 1, size: 1)
fmt.Printf("%p, size: %d, align: %d\n", &strObj, unsafe.Sizeof(strObj), unsafe.Alignof(strObj))
// 0xc00006e020, size: 32, align: 8As you can see in the result above, the data size of string is the same even though it has a long string.
Even though it’s Unicode, we can get the actual byte size by using len(). str2 has 2 length in Japanese but len() returns 6.
str1 := "123"
fmt.Printf("byte size: %d, length: %d, bytes: %v\n", len([]byte(str1)), len(str1), []byte(str1))
// byte size: 3, length: 3, bytes: [49 50 51]
str2 := "はい"
fmt.Printf("byte size: %d, length: %d, bytes: %v\n", len([]byte(str2)), len(str2), []byte(str2))
// byte size: 6, length: 6, bytes: [227 129 175 227 129 132]If it’s necessary to know the actual length, we need another way but it’s not a topic for this post.
Actual byte size of slice
As I explained above, the byte size of a slice is always the same.
arr := make([]int64, 0, 3)
fmt.Printf("%p, size: %d, align: %d\n", &arr, unsafe.Sizeof(arr), unsafe.Alignof(arr))
// 0xc0000aa060, size: 24, align: 8
arr = append(arr, 1, 2, 3, 4, 5, 6, 7, 8, 9, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 0)
arr = append(arr, 1, 2, 3, 4, 5, 6, 7, 8, 9, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 0)
fmt.Printf("%p, size: %d, align: %d\n", &arr, unsafe.Sizeof(arr), unsafe.Alignof(arr))
// 0xc0000aa060, size: 24, align: 8If we want the actual byte size, it must be calculated. In this example it’s len(arr) * 8 bytes. Don’t forget to add 24 bytes for the array representation that is explained above.
Sort the variables
We already know how to sort variables in a struct. Look at the following example.
type memory3 struct {
boolValue1 bool
boolValue2 bool
boolValue3 bool
boolValue4 bool
boolValue5 bool
boolValue6 bool
boolValue7 bool
boolValue8 bool
int32Value1 int64
int32Value2 int64
int32Value3 int64
int32Value4 int64
int32Value5 int64
int32Value6 int64
int32Value7 int64
int32Value8 int64
}
type memory3_2 struct {
boolValue1 bool
int32Value1 int64
boolValue2 bool
int32Value2 int64
boolValue3 bool
int32Value3 int64
boolValue4 bool
int32Value4 int64
boolValue5 bool
int32Value5 int64
boolValue6 bool
int32Value6 int64
boolValue7 bool
int32Value7 int64
boolValue8 bool
int32Value8 int64
}We might want to define a struct in the latter way, that is alternate declaration, when those data are one pair. However, it generates 56 bytes of difference. The difference will be big if the struct is a map or a big array.
sizeOfMemory3 := unsafe.Sizeof(memory3{})
sizeOfMemory3_2 := unsafe.Sizeof(memory3_2{})
fmt.Printf("%d, %d (diff: %d)\n", sizeOfMemory3, sizeOfMemory3_2, sizeOfMemory3_2-sizeOfMemory3)
// 72, 128 (diff: 56)If we really need to reduce memory usage, we should consider variable order in the struct. Otherwise, we should define the pair as a struct and use it in the original struct.


Comments